

2024.04.15 - [Lectures/Basic NLP] - Count based Word Representation
Count based Word Representation
2024.03.02 - [Lectures/Basic NLP] - Introduction & Word Vectors Introduction & Word Vectors Before the Start 스탠포드 강좌는 딥러닝을 배우는 모든 이들의 바이블이 아닐까? Andrew Ng(앤드류 응) 교수님 강좌를 듣고 나서 C
lazyhand.tistory.com
이번 글에서는, 통계 기반 Word Representation의 한계를 극복하기 위해 발전한 Machine-learning적 Word Embedding 기법들에 대해 알아보기에 앞서, 그 기반이 되는 언어 모델에 대해서 알아야하기에 이에 대해 먼저 알아보고자 한다.
Language Model
언어 모델이란 무엇일까?
언어 모델(Langug Model)은 단어 시퀀스에 확률을 할당(assign) 하는 일을 하는 모델이다.
가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것이다.
언어 모델링(Language Modeling)은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업을 말한다.
즉, 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일은 언어 모델링이라고 한다.
언어 모델을 만드는 방식에는 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 구분할 수 있다.
모두 알다시피, 최근 인공 신경망을 통한 방식이 더 발전하여 BERT, GPT와 같이 높은 성능을 나타내고 있다.
그러나, 자연어처리를 기초부터 공부하기 위해서는 통계적인 방식부터 알아봐야 하기에 통계적 방식부터 소개하겠다.
소개에 앞서, 헷갈릴 수 있는 개념이라 다시 짚고 넘어갈 부분이 있다.
바로 Language Model과 Wrod Representation의 차이이다.
Word Representation은 앞선 글에서 설명했듯이, 컴퓨터가 이해할 수 있도록 자연어를 수치화(벡터화)시키는 방식이다.
이는 자연어의 의미 관계를 포착하는 역할을 하는 것이다.
즉, Word Represenation은 언어 모델의 input으로 활용될 수 있으나, 그 자체를 언어 모델로는 볼 수 없다는 것이다.
다시 돌아와 통계적 언어 모델에 대해서 먼저 설명하겠다.
그 이유는, Sparse representation이후 사람들이 자연어 처리를 위해 고안한 방식은 우리가 지금 흔히 생각하는 Dense representation기반이 아닌 통계적 방식을 활용한 언어 모델이었기 때문이다.
Statistical Language Model (통계적 언어 모델)
Count 기반 접근
조건부 확률의 chain rule을 통하면 n개에 대한 조건부 확률은 다음과 같이 표현될 수 있다.
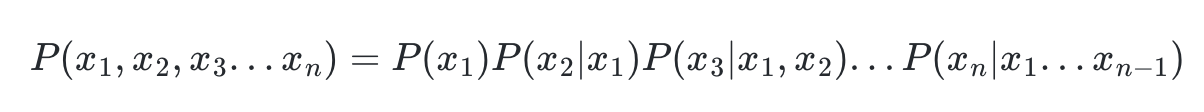
이러한 조건부 확률의 특성을 활용하면 밑의 예시와 같이 각 단어가 나타날 확률에 대해서 구하면, 문장에 대한 확률을 계산할 수 있다.

그렇다면 각 단어가 등장할 확률에 대해서 알아야 계산할 수 있는데 그것은 어떻게 계산할 수 있을까?
바로, 각 단어가 이전 단어들 묶음 다음으로 나타났던 횟수를 기반으로 계산하는 것이다.
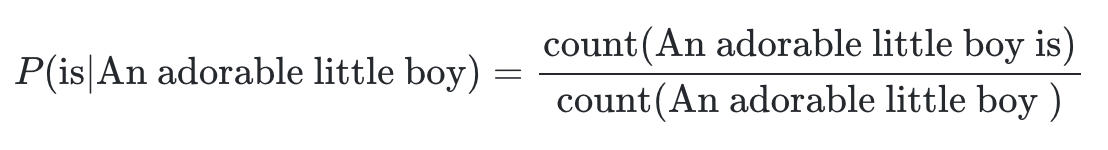
하지만, 이러한 카운트 기반의 접근은 Sparsity 문제를 가진다.
만약 모델이 학습한 corpus가 데이터를 가지고 있지 못해, An adorable little boy is라는 시퀀스가 없었다면 An adorable little boy 다음에 is가 올 확률은 0이 되어 버린다.
이 방식은 특정 Word Representation이 존재하기 보다는, 정말 각 시퀀스의 존재 확률로 언어 모델을 구성하는 방식이다.
N-gram Language Model
카운트 기반의 접근 방식의 Sparsity 문제를 완화시킬 수 있는 방식이다.
앞서 An adorable little boy is라는 시퀀스가 없다면 An adorable little boy 다음에 is가 올 확률은 0이 되어 버린다고 했는데, 이를 boy is라는 시퀀스로 확률을 계산한다면 어떨까?
An adorable little boy is라는 시퀀스 보다 더 많이 등장할 확률이 높아진다.
이를 통해, An adorable little boy 다음에 is가 올 확률과 boy 다음에 is가 올 확률을 동일하게 간주하는 방식이 N-gram Language Model이다.

여기서 N은 그럼 무엇을 의미하는가?
바로 기준 token보다 몇 개의 token까지의 시퀀스를 기준으로 할 것인지를 의미한다.
다음은 An adorable little boy is spreading smiles라는 문장에 대한 N-gram의 예시이다.
unigrams : an, adorable, little, boy, is, spreading, smiles
bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles
4이상의 경우 부터는, 각 숫자를 앞에 붙여서 사용한다.
하지만, 여전히 N-gram 역시 문제점을 가진다.
1. 여전한 Sparsity 문제
카운트 기반 접근 방식에 비해 Sparsity 문제를 완화시킬 수 있지만, 여전히 N-gram에 대한 시퀀스가 존재하지 않는다면 확률을 계산할 수 없는 Sparsity문제가 발생한다.
2. N 선택에 대한 trade-off 문제
어떤 시퀀스는 N이 2일때 가장 많이 등장하지만, 다른 시퀀스는 N이 3일때 가장 많이 등장할 수 있다. 이렇게, N을 선택하는 것에 따라 어떤 것에 대해서는 손해가 어떤 것은 이득을 볼 수 있는 trade-off 문제가 발생한다.
그럼 과연 가장 많이 등장하기 쉬운 N이 1일때가 가장 좋은 N의 선택일까?
당연하게도, 그렇지 않다.
물론, 가장 적은 1을 N으로 선택한다면 학습에서는 가장 적합하고 높은 성능을 보이겠지만 실제 Test 데이터에 대해서는 맞출 확률이 낮아지기 때문이다.
그렇기에, 너무 적지도 너무 크지도 않은 N을 선태하는 것이 중요하게 작용한다.
여기까지가 통계적 기법을 기반으로한 언어 모델이다.
다음 글에서는 다시 돌아와 통계 기반 Word Representation의 한계를 극복하기 위해 발전한 Machine-learning적 Word Embedding 기법들에 대해 알아보겠다.
'Lectures > Basic NLP' 카테고리의 다른 글
| Count based Word Representation (0) | 2024.04.15 |
|---|---|
| Introduction & Word Vectors (0) | 2024.03.02 |

