

Before the Start
스탠포드 강좌는 딥러닝을 배우는 모든 이들의 바이블이 아닐까?
Andrew Ng(앤드류 응) 교수님 강좌를 듣고 나서 CS224N과 CS224W존재를 알게 되었다.
그전까지는 인터넷을 돌아다니며 여러 자료를 통해 공부를 하게 되었는데,
가장 어느정도 깊이까지 다루는 곳은 아무래도 대학교 강좌들이다.
가장 간편하게 보았던 것은 짧게 개념정리하기 좋은 허민석 님의 유튜브였고,
그 다음으로는 강필성 교수님 강의였다. (물론,, 이리저리 해서 이건 다 보지 못했다...ㅎ)
아무튼 현재 나에게 자연어처리는 이래저래 내가 연구하는 부분들만 공부하다 보니 전체적 흐름이 조금 덜 정리되어 있던 상태이다.
그러다, 현재 빠르게 봐야하는 일이 좀 생겨서 급하게 자연어처리 입문 부분을 다시 정리하고자 한다.
결론적으로, 여러 자료들을 조금 훑어보다가 시간 상 짧고 필수적인 요소를 모두 가지고 있는 위키독스 딥러닝을 이용한 자연어 처리 입문 내용을 토대로 필수 개념들만 먼저 정리하고자 한다.
(다른 내용이지만, 위키독스에 도움 되는 다양한 자료들이 있으니 관심 있으신 분들은 살펴보면 좋을 것 같다.)
https://wikidocs.net/book/2155
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
Introduction
가장 기본적으로 컴퓨터가 자연어 처리를 하기 위해서는 어떻게 해야 할까?
먼저, 컴퓨터가 이해할 수 있는 숫자로 자연어를 표현해야 한다.
이것을 바로, Word Representation이라고 한다.
Word Representation은 가장 포괄적인 개념으로, 컴퓨터가 이해할 수 있는 어떠한 형태로든 자연어를 변환한 것을 의미한다.
그럼, 가장 간단한 Word Representation은 무엇일까?
바로 1 Hot Encoding(원-핫 인코딩)이다.
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 밑에 그림처럼 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이다.

당연하게도, 이런 부분들은 단어의 개수가 늘어날수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다는 단점이 있다.
즉, 표현하고 싶은 단어가 늘어날수록 벡터의 차원이 증가하게 된다.
또한, 원-핫 인코딩은 단어들 간의 유사도 계산도 표현할 수 없다는 단점을 가진다.
이를 해결하는 방법이 바로 단어들을 context에 따라 어떠한 표현을 가지게 하는 것이다.
바로 단어의 잠재 의미를 반영하여 다차원 공간에 벡터화하는 기법이라고 할 수 있다.

Word Vector
그럼, 어떻게 단어들 마다 각 표현을 가질 수 있게 할까?
여기에는 아주 다양한 방식이 존재한다.
그중 현재 가장 유용하게 사용되는 Word Representation 방식의 기본이 되는 것은 Word Vector이다.
단어 별로 Dense 한 숫자들의 그룹을 구성해서 해당 그룹이 한 단어의 표현 즉, vector의 값이 되는 방식으로 모든 단어들이 고유한 vector의 값을 같도록 하는 것이다.

이렇게, 각 단어를 표현하게 되면 모든 단어들은 서로 간의 유사도를 계산할 수 있게 된다.
이를 기반으로 나아가, 이런 vector 값을 통해 단어들을 Embedding space에서도 표현할 수 있게 된다.
이러한 방식을 Word Embedding이라고 하며, 현재 사용되고 있는 Deep-learning 기반에서 가장 많이 사용된다.
이렇게 모든 단어들을 Embedding space에 표현하게 되면, 유사한 단어들은 유사한 vector의 값을 가지기에,
Embedding space 내에서도 서로 가까운 곳에 위치하게 되는 것을 발견할 수 있다.

Category of Word Embedding
결국 Word Representation은 Word를 Vector화하는 모든 기법을 의미하며, 이의 하위 개념이 Word Embedding으로 볼 수도 있다.
그럼 이제 슬슬 개념간의 차이가 조금 무색해지기 시작한다.
많은 경우 혼용을 하거나, 큰 상관 없이 사용하는 경우도 있긴 하지만 내가 정리한 바는 아래와 같다.
다시 돌아와 명확히 말하자면, Word Representation은 최상위 개념으로 컴퓨터가 이해할 수 있도록 표현한 숫자들이다.
그리고 숫자들을 어떻게 표현하는 지에 대한 관점으로 바라보면 이를 다음 2가지로 나눌 수 있다.
- Sparse representation: Representation 내 숫자들에 0이 많이 나타나는 경우
- Dense representation: 0이 많이 나타나지 않고 본래의 정보들에 비해 집약적으로 소수의 숫자들로 표현하는 경우
당연하게도 Sparse의 경우 계산량이 높고 비효율적이며, Desne의 경우가 계산량이 낮고 효율적인 방식이다.
앞으로 알아볼 전통적인 방식인 Count based Word Representation에 속하는 경우가 이에 해당한다.
하지만, 이는 전통적인 방식인 경우에만 해당하고 대부분의 경우 Dense representation에 속한다.
그리고 이를 위해 필요한 대표적인 방식이 바로 Word를 Vector로 표현하는 Word Embedding이다.
(물론, 전통적 방식인 Count based Word Representation의 확장인 Statistics based Word Representation으로도 Dense representation을 구현 할 수도 있다. ex) LSA, PMI 추후 이에 대해 소개도 하겠지만, 이는 적은 경우에 해당한다.)
Sparse representation의 경우 사실 명확하게 보면, Word를 숫자로 표현은 하나 Dense하게 표현하지 않고 단어 간의 의미적 관계를 표현하지 못하기에 Vector로 보기에는 애매한 부분이 있는 것이다. 그러나, 전통적인 경우 외에는 Dense하게 표현되기에 Word Representation과 Word Embedding이 혼용되어 사용이 많이 되게 되었다. 또한, Deep-learning 방식으로 나아간 현재 Word Embedding 관점으로 방식을 Category화 하는 것이 이해하기 쉬어서 혼용이 되기 시작한 것도 같다.
아래 그림 역시 그런 관점으로 분류된 대표적인 Word Embedding Model들을 나타낸다.
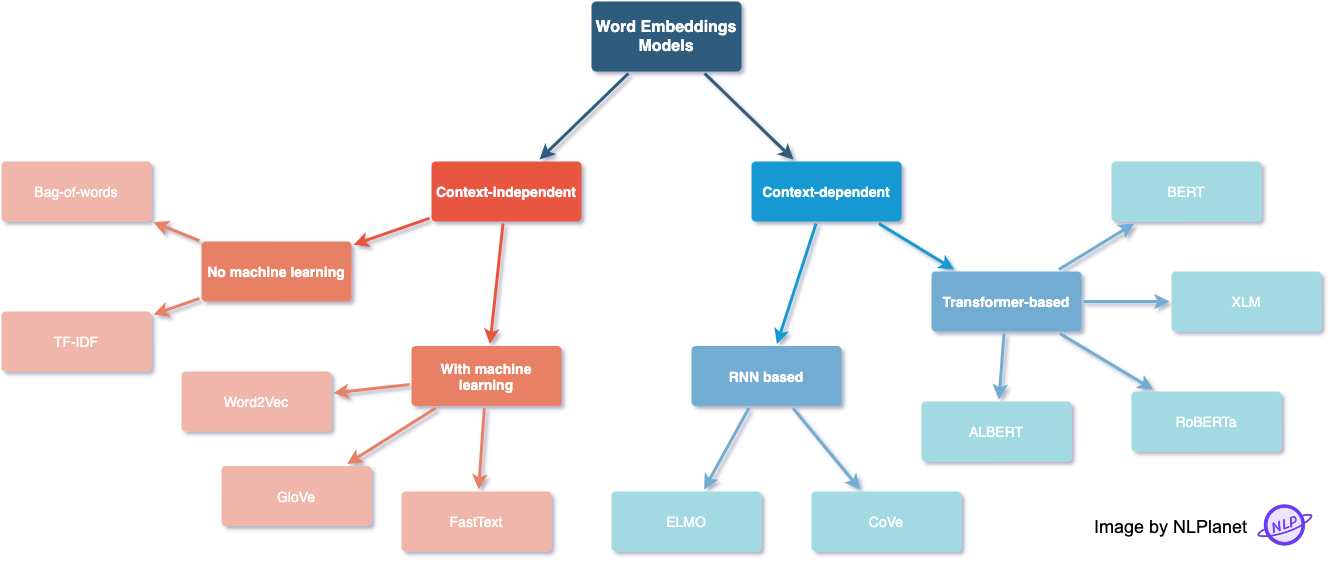
각 방식들 중 중요한 부분들에 대한 내용들은 다음 글에서 나누면서 차근차근 다루도록 하겠다.
'Lectures > Basic NLP' 카테고리의 다른 글
| Language Model (0) | 2024.04.17 |
|---|---|
| Count based Word Representation (0) | 2024.04.15 |

